
INTRODUCTION
主要解决了两个问题:
- Generalization Reduction & High-Level Features.
- [CANet: Classagnostic segmentation networks with iterative refinement and attentive few-shot learning]指出high-level feature cause performance drop. (估计是因为使用high-level feature会使得模型泛化能力变弱)
- 他们用imagenet上pre-train出来的模块,生成“prior”。因为prior是用high-level feature训练出来的,并且只是在imagenet上训练,所以不失generalization ability。
- Spatial Inconsistency.
- 因为support image有限,有时候support image和query image上的物体的姿势之类的可能变化很大。他们提出了Feature Enrichment Module,去解决这个问题。
RELATED WORK
Few-Shot Learning
- meta-learning
- 跟memory有关。似乎是基于RNN的模型(比如LSTM)修改的。
- metric-learning
- Prototypical network
- 这篇文章比较偏向于metric-learning
METHOD
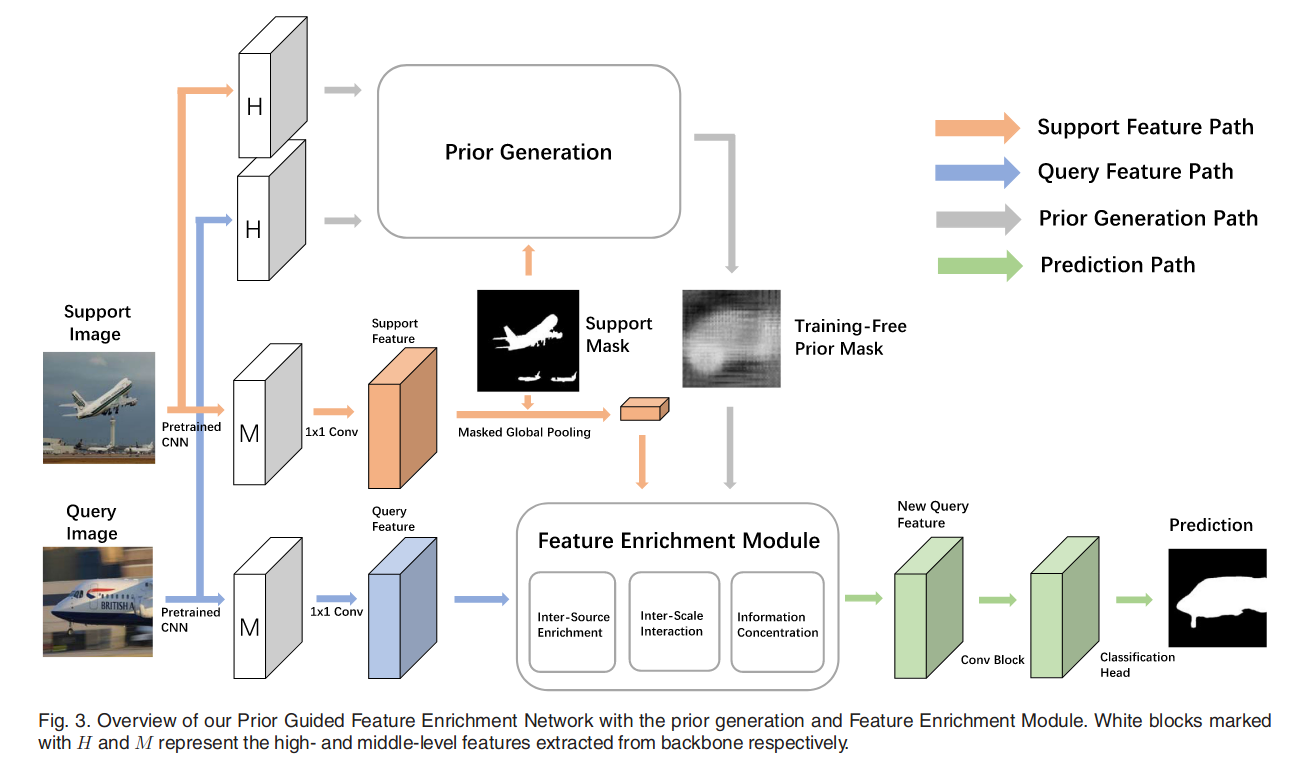
Prior for Few-Shot Segmentation
CANet表现好主要是通过backbone提取了middle-level feature,并且CANet说middle-level里面有unseen class的object part。但是我们的解释与之相反。
Prior Generation的具体做法
先利用backbone network对输入的query和support进行特征提取,其中$M_S$代表Supprort image mask $$ X_Q=F(I_Q), \ X_S = F(I_S)\times M_S $$
$Y_Q$表征了$X_Q$和$X_S$在像素维度上的一致性。如果一个$X_Q$上的像素在$Y_Q$上有比较大的值,说明这个像素在support image上更有可能有至少一个像素。为了计算$Y_Q$,首先计算cosine similarity $$ cos(x_q,x_s)=\frac{x_q^Tx_s}{|x_q||x_s|},\ \ \ \ q,s\in{1,2,…,hw} $$
对每一个$x_q \in X_Q$来说,取其中最大的值作为correspondence value $$ c_q = max_{s\in {1,2…,hw}}(cos(x_q,x_s)) $$
$$ C_Q = [c_1,c_2,…,c_hw] \in R^{hw\times1} $$
把$C_Q$ reshape 到h*w*1的空间,作为$Y_Q$,然后做一个normalization $$ Y_Q = \frac{Y_Q-min(Y_Q)}{max(Y_Q)-min(Y_Q)+\epsilon} $$
Feature Enrichment Module
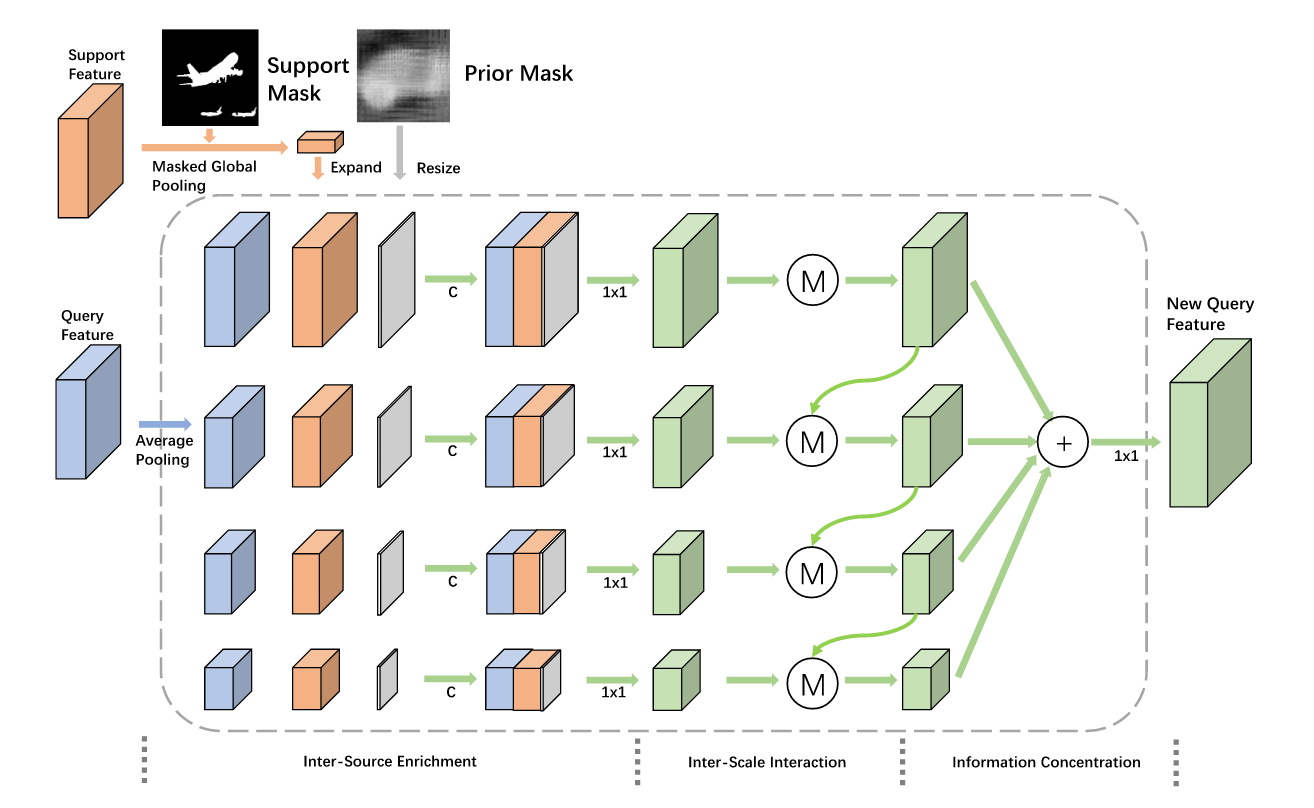
将support image和query image关联起来的方法
- 对support image做global average pooling
- 不用说都感觉效果一般
- multi-level spatial information
- 说有两点不好,分别是merge的时候缺少specific refinement,和relation across different scales is ignored。这两点看看就好了,我感觉作者说有这两点问题主要是他自己在这两点做了一些trick。
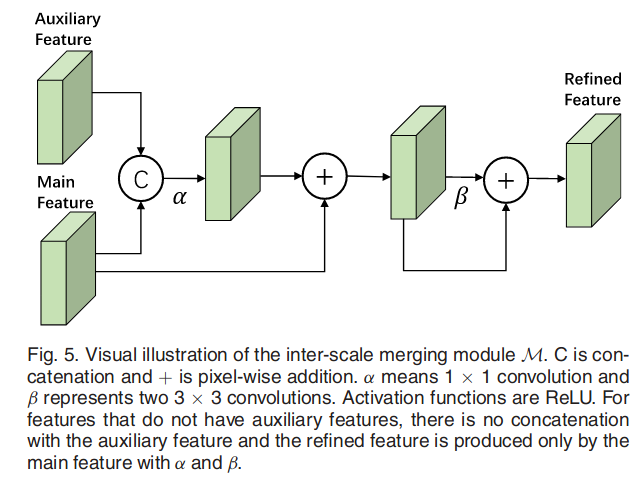
作者提出的FEM可以很好的解决问题。其中M的具体操作如下
Loss Function
$$ L = \frac{\sigma}{n}\sum_{i=1}^{n}{L_1^i+L_2} $$
主要选用交叉熵作为损失函数。
- $L_1^i$ FEM出来的n层spatial size中的第i层的X,通过intermediate supervision生成
- 具体来说,这个X应该是FEM模块中,每一层的feature在information concentration之前,interpolate后做交叉熵的值
- $L_2$ 最后prediction和label的交叉熵。