One-shot Affordance Detetion 2106.14747.pdf (arxiv.org)
Abstract
- 可供性检测就是通过一张图片识别物体潜在的动作。
- OS-AD网络可以在所有候选图片中帮助发现普遍的可供性,并且学会适应感知未发现的可供性。
- 他们建立了一个数据集PAD :4k Image;31 affordance;72个物体类别
Introduction
- 挑战OS-AD 给一张图片,告知其图片上的物体的行为,则可以察觉所有物体普遍的可供性
- 问题:现实生活中一个物体可能有多个affordance(例如沙发可以躺也可以睡),而具体用什么affordance取决于人在这个场景中的目的。抛去目的的指引,直接从一张图片中学习affordance会导致忽略了其他视觉上的对此时的任务有效的affordance
- 从行为中找暗示
- 采用collaboration learning去捕捉不同物体间的潜在关系,抵消物体不同的appearance,增加泛化性;OS-AD PLM,PTM,CEM
- 可供性检测应该能适用于各种环境: PAD 目标驱动可供性数据集
Related work
- Affordance Detection
- One-Shot Learn
- based on metric learning using the siamese neural network 度量学习;孪生神经网络
- meta-learning and generation models 元学习
Methods
Framework
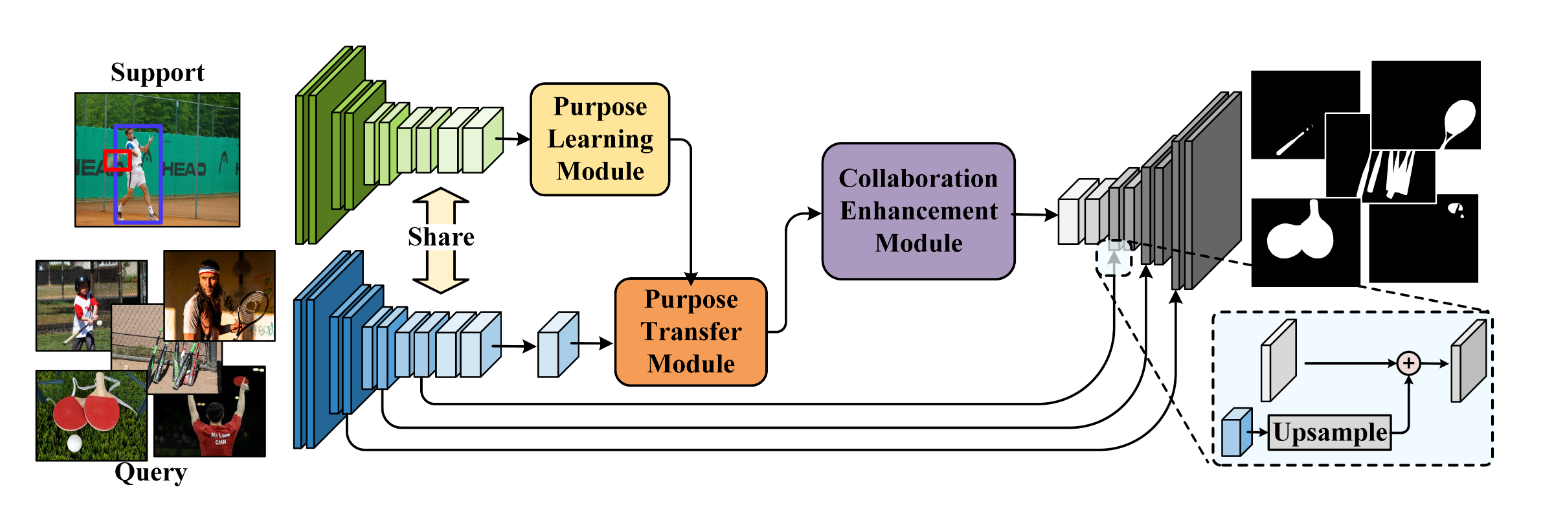
- input: query images, human-object interactions
- ResNet50 -> 获得图像表现 $X$ and $ X_{sup} $
- 输入$X_{sup}$和 人和物体的边界矩阵到PLM -> 提取human-object interaction信息,对action-purpose编码,发现人想要旋转的原因
- 输入feature representation和$X$到PTM里面 -> 让网络学会处理带affordance的信息
- 输入encoded feature 到CEM, 输出affordance
Purpose Learning Module
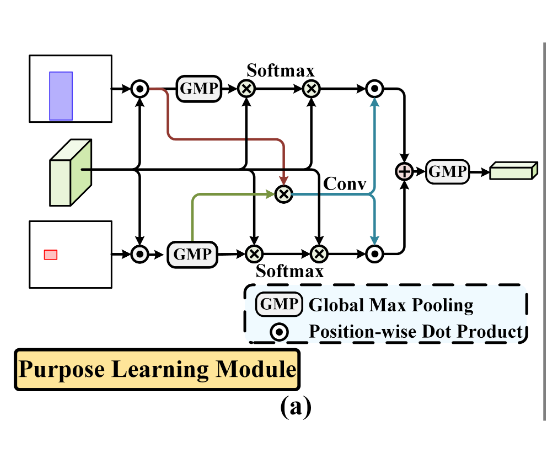
:star:On Exploring Undetermined Relationships for Visual Relationship Detection受到了这篇文章的启发,说instance(人或物)的特征可以指导网络哪里应该focus。
先得到$M_O$和$M_H$ (这两者分别代表什么?作者说是为了让模型去分别focus on物体和个人,引入了注意力机制,其中GMP的作用是得到最显著的特征) 其中⊗ 代表element-wise product,元素对应位置相乘,$f_O$和$f_H$是$X_O$和$X_H$进行 global maximum pooling(GMP)后的值 $$ M_O = Softmax(f_O⊗X_{sup})⊗X_{sup} \ M_H = Softmax(f_H⊗X_{sup})⊗X_{sup} $$ 作者说他们用$f_O$去指导网络应该focus on人物交互$M_{HO}$ $$ M_{HO}=Conv(f_O⊗X_H) $$ 最后得到encoding of the action purpose $F_{sup}$,其中" ·“代表position-wise dot product. $$ F_{sup} = MaxPooling((M_{HO}·M_H)+(M_{HO}·M_O)) $$
- 输入:$X_{sup}$以及人和物体的边界框
- 输出:动作目的编码 $F_{sup}$
Purpose Transfer Module
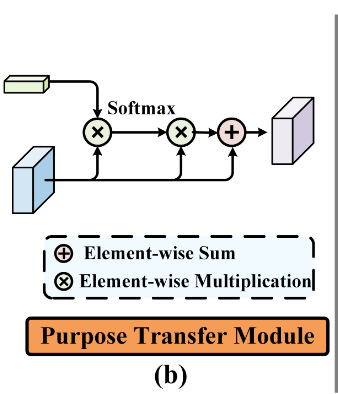
通过attention机制,将action purpose传递到query image中,加强相关features $$ X_{T_i} = X_i + Softmax(X_i⊗F_{sup})⊗X_i,\ where\ i \ in\ [1,n] $$
Collaboration Enhancement Module
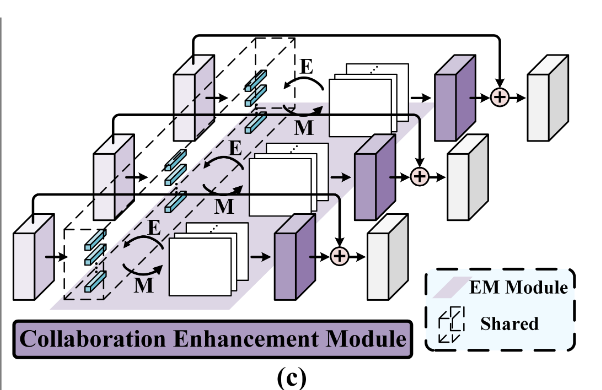
交替使用E-step和M-step,得到一个紧凑的基集,重建query image的特征图。
从PTM输入的$X_T = {X_{T_1},…,X_{T_n}}$经过卷积得到$F={F_1,…F_n}$
初始化基集$\mu$
E-step估计隐变量$Z={Z_1,…Z_n}$
- 第k个basis 第j个像素 第i个图片
- $Z_{ijk} = \frac{\kappa(f_{ij},\mu_k)}{\sum_{l=1}^{K}\kappa(f_{ij},\mu_l)}$
- $f_{ij}$第i个图像的第j个位置的特征
- $\kappa$是指数核函数
M-step更新基集$\mu$,并把$\mu$作为$F$的加权平均
- $\mu_k = \frac{\sum_{i=1}^n\sum_{j=1}^Lz_{ijk}f_{ij}}{\sum_{i=1}^n\sum_{j=1}^Lz_{ijk}}$
经过E-M的迭代后,我们用$\mu$和$Z$去重建$X$并得到$F$
- $F_i=Z_i\mu$
- $\tilde X_i=X_i+Conv(F_i)$
前景知识
Expectation-Maximization (E-M)
- 初始化参数
- 根据初始化的参数,划分类别
- 根据最大似然估计重新计算参数
- 重复步骤1-3,迭代n次,参数收敛
期望最大化注意力机制
- https://www.jianshu.com/p/6bb799d256b1
- 作者写的知乎专栏:https://zhuanlan.zhihu.com/p/78018142
分为$A_E,A_M,A_R$三部分组成,前两者是EM算法的E步和M步
- 假定输入的特征图为$X\in R^{N\times C}$,基初始值为$\mu\in R^{K\times C}$
- $A_E$步估计隐变量$Z\in R^{N\times K}$,则第k个基对第n个像素的权责可以计算为
- $z_{nk}=\frac{\kappa(x_n,\mu_k)}{\sum_{j=1}^{K}\kappa(x_n,\mu_j)}$
- 实现时可以用公式 $Z=softmax(\lambda X(\mu^T))$,其中$\lambda$作为超参数控制$Z$的分布
- $A_M$步更新基。$\mu$被计算为$X$的加权平均。第k个基被个更新为
- $\mu_k=\frac{\sum_{n=1}^Nz_{nk}X_n}{\sum_{n=1}^Nz_{nk}}$
- $A_E$和$A_M$交替执行T步后,$\mu$和$Z$近似收敛,可以用来对X重新评估
- $\tilde X=Z\mu$
Decoder
$$ P^m_i=Conv(Unsample(Conv(X^m_i)+P^{m+1}_i)),\ where\ m \ in \ [1,4] $$
- 其中m是第m层,i表示
把检测结果在与原图相同的特征维度还原出来
用交叉熵Cross-entropy来作为损失函数
Experiments
- k-fold evaluation protocol 将数据集分成三部分,其中之二作为训练集,剩下作为测试集
Benchmark Setting
- IoU metric
- for segmentation task 切割任务
- Mean Absolute Error (MAE)
- measure the absolute error between the prediction and ground truth
- E-measure 相关文章 E-measure: Enhanced-alignment Measure for Binary Foreground Map Evaluation
- a metric that combines local pixels and image-level average values to jointly capture image-level statistics and local pixel matching information.
- Pearson Correlation Coefficient (CC)
- 皮尔逊相关系数 两个变量之间的协方差和标准差的商 $$ p_{X,Y}=\frac{cov(X,Y)}{\sigma_x\sigma_y} $$
- measure the correlation between prediction and ground truth
其他训练参数
- Adam optimizer
- resnet50
- The input is randomly clipped from 360×360 to 320×320 with random horizontal flipping. 随机裁剪+水平翻转
- 40 epochs on 1080ti
- learning rate 1e-4
- the number of bases in CEM is $K=256$
- E-M 迭代次数 3
Quantitative and Qualitative Comparisons
对比下来就是我们的模型很好很好