
Introduction
CNN The intrinsic characteristics impose crucial inductive biases for image processing. (平移不变性等)
Self-Attention The flexibility enables the attention module to focus on different regions adaptively and capture more informative features. ( bigger receptive field )
Generally, we owed self-attention based model’s great performance to the global receptive field it have.
Considering the different and complementary properties of convolution and self-attention, there exists a potential possibility to benefit from both paradigms by integrating these modules.
Contribution:
- A strong underlying relation between self-attention and convolution is revealed
- An elegant integration of the self-attention and convolution module, which enjoys the benefits of both worlds
Method
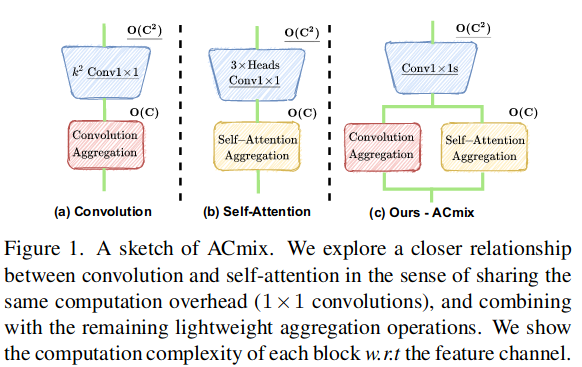
Conv
( This can be better illustrated by image a )
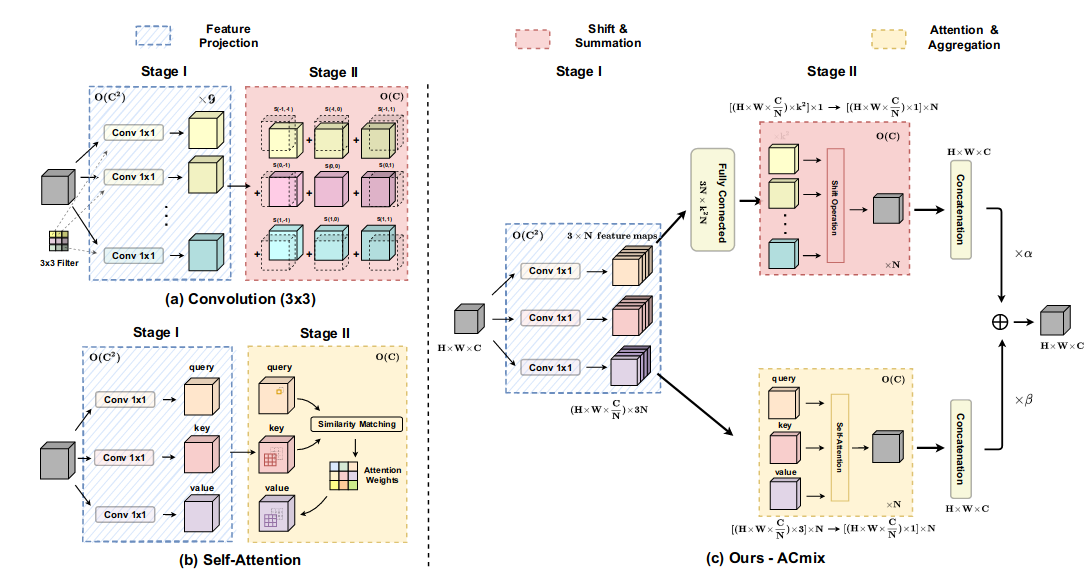
They decompose the Conv with K*K kernel to two stages. On the first stage, K*K kernel can be seen as many 1*1 kernel. On the second stage, we can gain finally feature map by shift each feature map and sum them.
Self-attn
( This can be better illustrated by image b )
Like Conv, they treat self-attn with two steps. Firstly, 1*1 kernel conv ( euqal to Fully Connected Network) can be used to generate query, key and value. Then, they use query and key to gain weight and put it on the value.
ACmix
The first stage of Conv and Self-attn can be shared. In the second stage, there are two paths which corresponds to each paradigm. Then, two learnable parameters $\alpha$ and $\beta$ is set for reweighting each feature map for sum up.
Shift
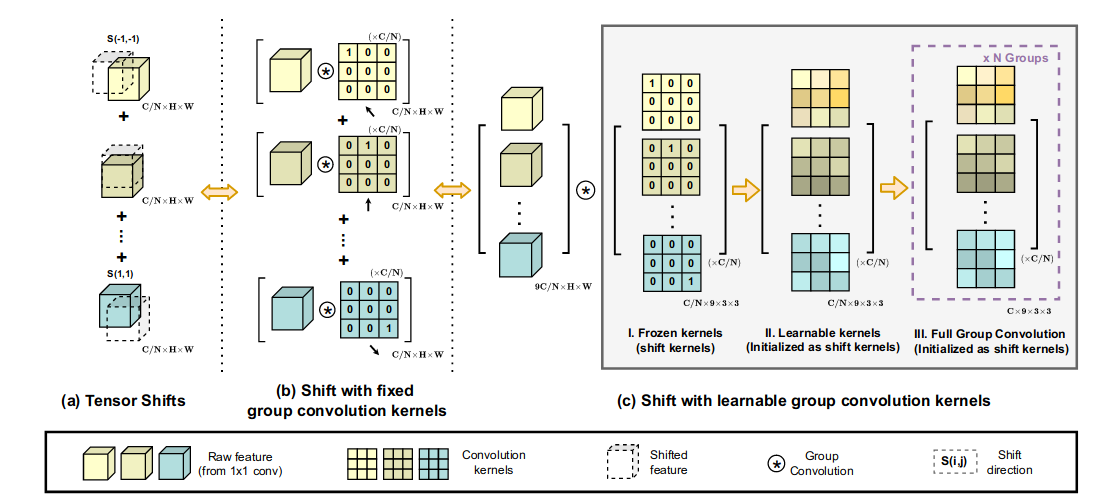
In the Conv path, they add a small trick compared to normal Conv.
Shifting tensors towards various directions practically breaks the data locality and is difficult to achieve vectorized implementation. This may greatly impair the actual efficiency of our module at the inference time. ( This part I don’t understand perfectly)
As a remedy, they turn to apply depthwise convolution with fixed kernels. Here comes to a question. Now that you use conv kernel to shift feature map, why not make it learnable? So they use learnable kernels and initialized as shift kernels.
Experiments
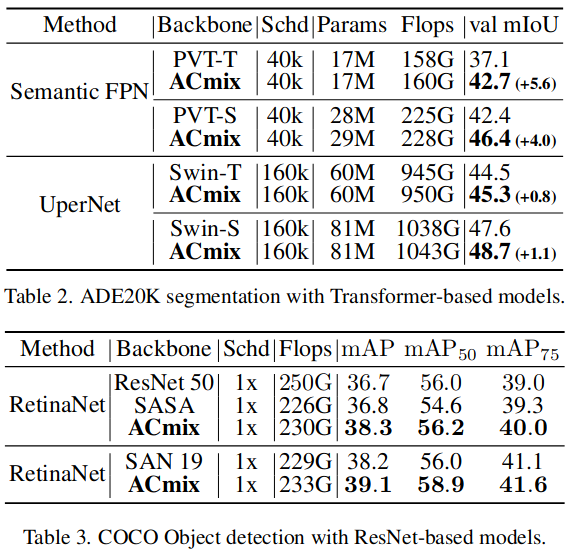
The idea is quite simple. So They need strong experiments result to support them. They use their module in many models and many task( classification, detection and segmentation ). All seems good.
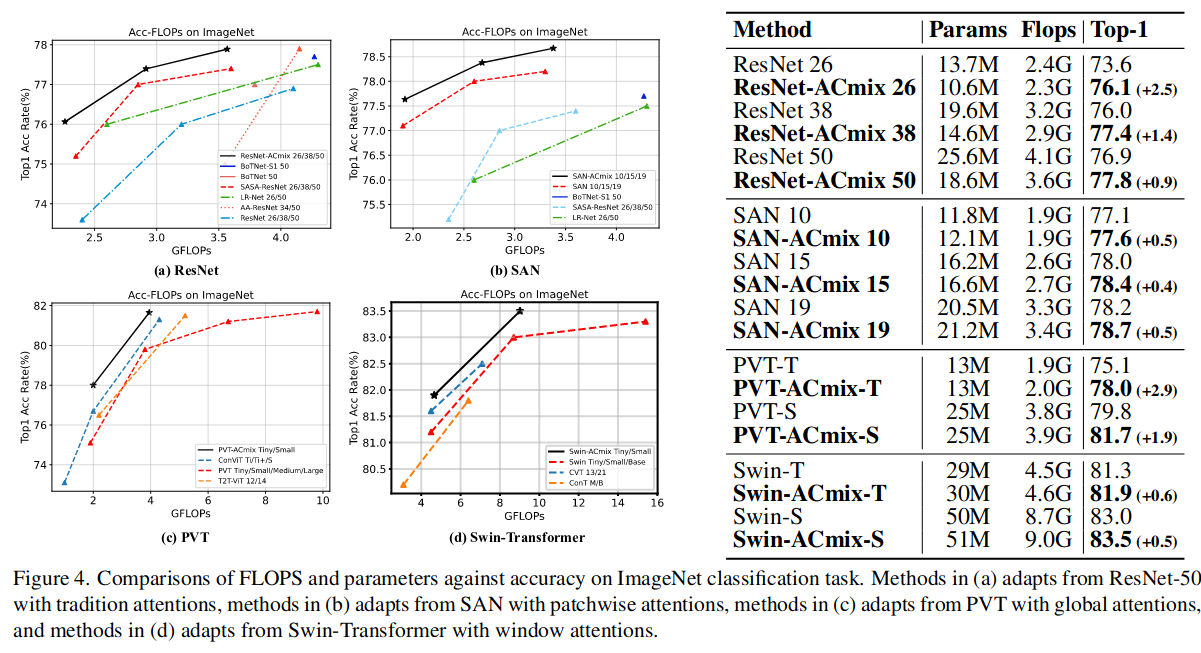
alpha and beta
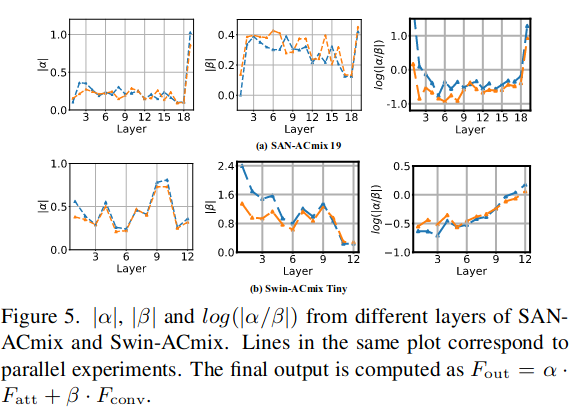
At last, they check $\alpha$ and $\beta$ in each layer. This leads to a interesting conclusion. We can see that at early stage $\beta$ take dominate position. This means Conv is a good feature extractor. But at the last stage, self-attention shows superiority over convolution.
This is also consistent with the design patterns in the previous works where self-attention is mostly adopted in the last stages to replace the original 3×3 convolution, and convolutions at early stages are proved to be more effective for vision transformers