
ABSTRACT & INTRODUCTION
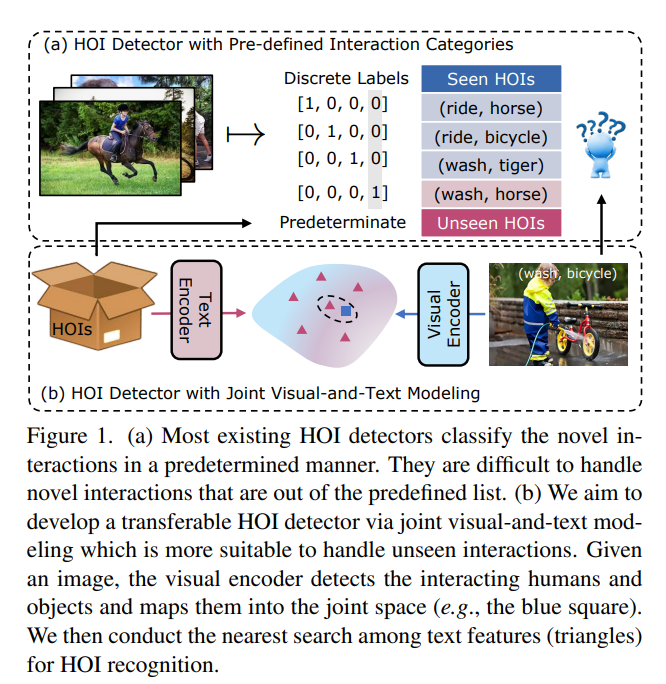
这篇文章的工作是,输入一张图片,输出HOI特征,并且用HOI短语作为监督训练(基于CLIP)。
他与其他HOI transfer工作不同的点在于,之前的工作对unseen object都是用discrete label作为输出,得到HOI。但是这就要求label中对应的HOI(就是每个动作)都预训练过,很难去识别interaction that out of the predefined list。这篇的思路主要是对文字和图像同时encode,然后寻找最近的匹配对,所以不存在这个问题。
METHOD
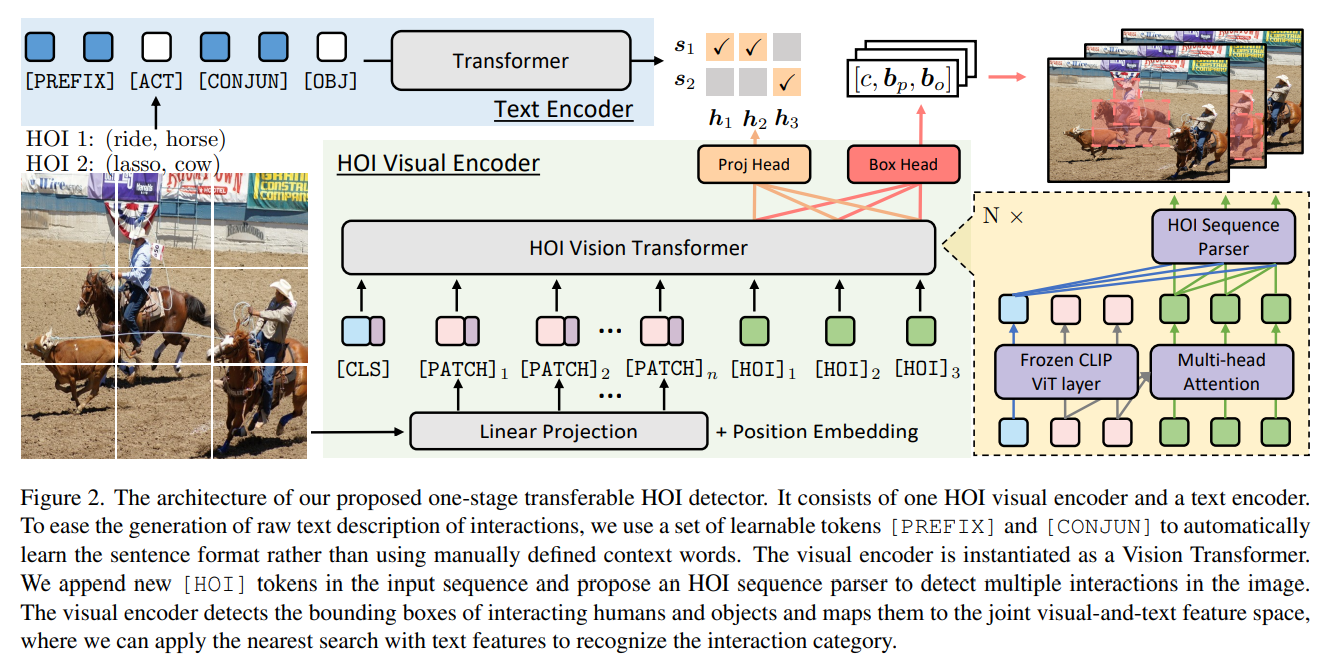
他们定义了HOI为 ${(b_p,b_o,a,o)}$(有些文章定义为triplet,其实都差不多,最重要的是verb),其中$b_p$和$b_o$是人和物的bounding box。$a$和$o$分别是human action和object category。
PRELIMINARY
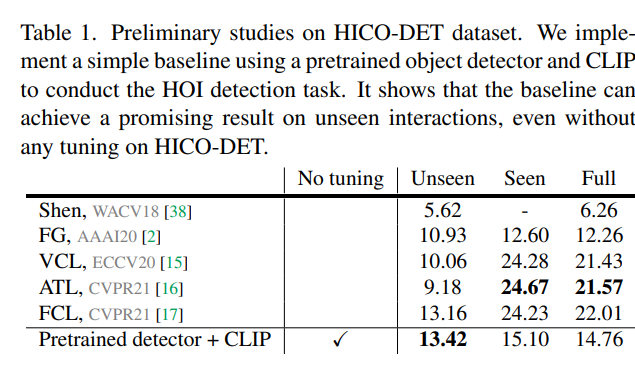
在preliminary中,他们简单设想了一些步骤,用Faster RCNN得到bounding box然后输入到CLIP,就能在Unseen数据集上得到SOTA,even without tuning.(废话,人家设计的时候也没管unseen HOI啊)
PROPOSED METHOD
visual input: ${(h,c,b_p,b_o)}$,
- h is feature representation for interactions
- $b_p,b_o$ is bounding box
- c is the confidence score for bounding box prediction
text encoder: raw text of interactions
similarity $h^Ts$, where h, s denote the output of visual encoder and text encoder. They are semantic features in the same dimension.
ViT-based Visual Encoder
前半部分输入跟ViT一样,对图像分patch之后加position embedding,在首位置插入CLS后直接作为输入放到ViT中。其中,关于CLS的理解如下
CLS的特点
- 不基于图像内容
- 位置编码固定
好处
- 该token随机初始化,能够编码整个序列的统计特性
- 本身不基于图像内容,避免对某个特定的token产生偏向性
但是和ViT不同的是,这里期望能识别出多种不同的HOI(ViT最开始是做分类任务的)。所以在原本的序列后面另外加入了M个CLS(留了M个空让网络自己去学)。
然而,输入的patch(以下称为X)和作为HOI的CLS(以下称为H)在ViT中作计算时亦有不同。
X就是正常经过Transformer block,不管H。其中MHA是多层注意力机制,LN是layer norm,MLP是2层感知机。 $$ X_l^{’} = MHA(X_{l-1})+X_{l-1} \ X_l = MLP(LN(X_l^{’}))+X_l^{’} $$ H在做多层注意力机制时,需要聚合来自X的信息(但是不需要位置0的CLS,他们说如果不mask的话,HOI会直接copy位置0的信息) $$ H_l^{’}=MHA(H_{l-1},X_{l-1}^{[1:]}) + H_{l-1} \ H_l = MLP(LN(H_l^{’}))+H_l^{’} $$ HOI Sequence Parser
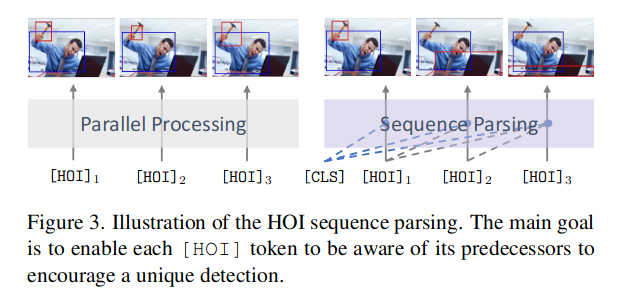
从transformer block出来的HOI序列有一个问题,没办法区分开来。这其实也好理解,因为输入的时候并没有带位置信息,实际上H之间都是等效的。
所以作者故意在这个模块中使用Sequence manner 而不是 in parallel的方式。
Project Head and Bounding Box Regressor
Project Head其实就是一个线性层,把从transformer block出来的X映射到text encoder的输出的维度,方便做相似度计算,从而找到最近的tensor。
LOSS
LOSS部分没有很复杂,由两部分组成,分别是box head输出和project head的loss $$ L_m(i,\phi) = L_b(\hat{b_p^i},b_p^{\phi_i})+L_b(\hat{b_o^i},b_o^{\phi_i})+L_h(\hat{h_i},s_{\phi_i}) $$ 其中$L_b$表示Bounding box 的loss,$L_h$代表CLIP那边的loss,包括text-to-visual和visual-to-text