
ABSTRACT & INTRODUCTION
从Few-shot learning角度,这篇也是基于metric-based的(我都没看到过几篇meta-based的文章,不知道是不是已经被淘汰了)
Motivations->现在的FSS主要有俩问题
- 会把不属于本类的物体也分割进来
- 分不清边界
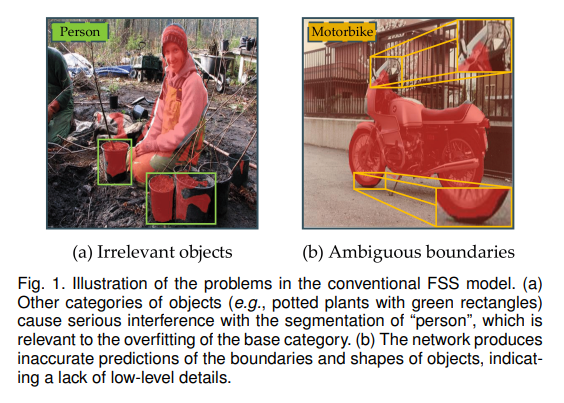
对于第一个问题,他们说在meta-training阶段就让模型直接学会识别base-dataset,这样后面做test的时候,如果说一个物体在train的时候见过,那么这个物体肯定就不是要分割的物体了(好像有点transductive了哈,但是严格说又不是)
The proposed Prototype Activation Module (PAM) integrates the base prototypes with the current novel prototype to form a holistic prototype set, and then activates the region of each target in the query image based on this set. If the object area is activated with high confidence by base prototypes, the corresponding location will be erased in the final activation map (i.e., set to 0)
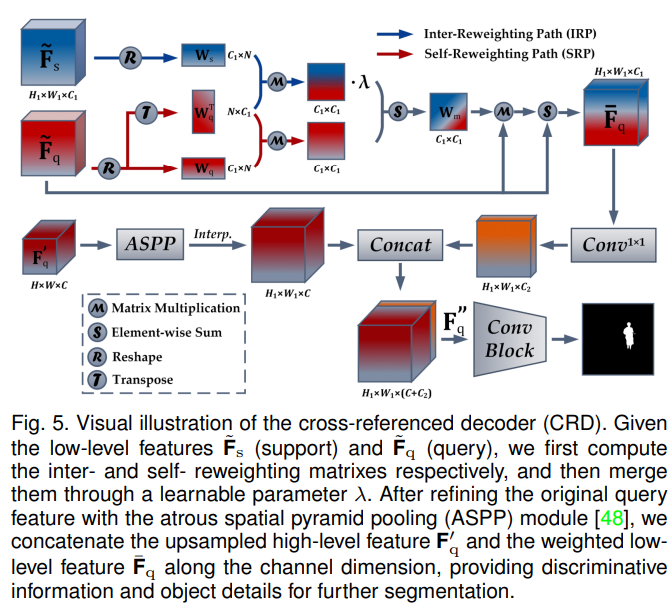
对于第二个问题,他们说关键就是要找出support和query中的本质联系(0.0),他们提出了基于DeepLabv3的CRD模型来解决这个问题。
We argue that, with limited samples available, the crux of improving foreground activation accuracy is to capture the co-existence characteristics between support and query images
METHOD
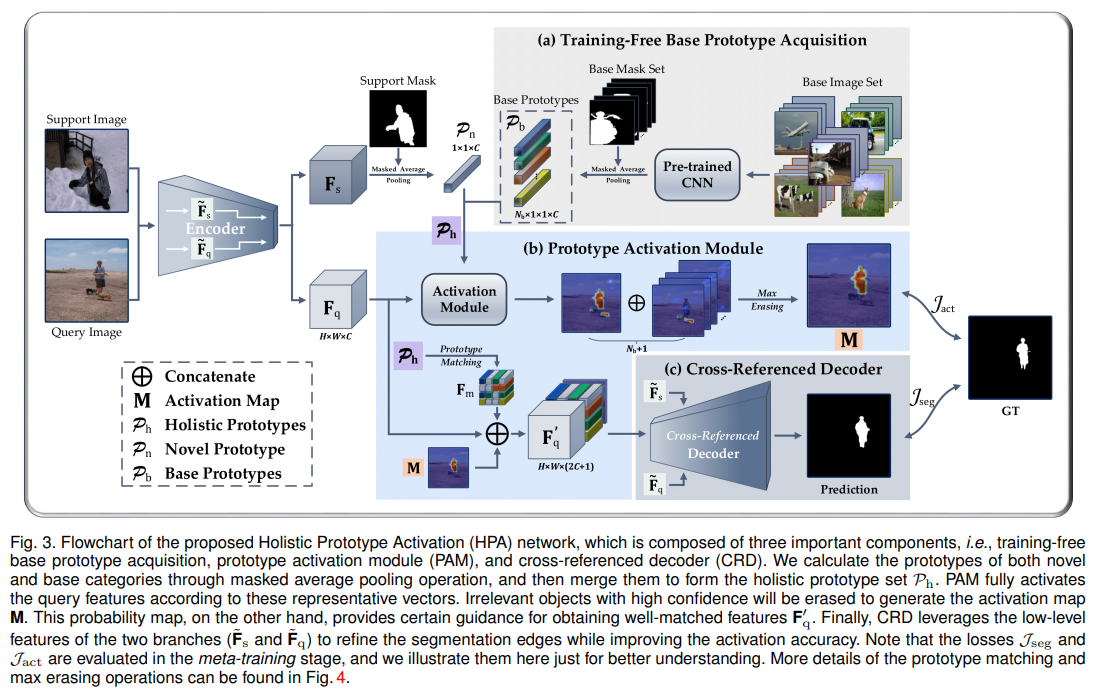
PROTOTYPE ACQUISITION
在这个模块生成base class的prototype $$ P_b^c = \frac{1}{N}\sum_{i=1}^{N_c}\frac{1}{|\hat{L_c^i}|}\sum_{j=1}^{HW}F_c^{ij}\hat{L_c^{ij}} $$ 其中$P_b^c$代表了class c的原型,size = 1x1xC。$F$,$\hat{L}$分别是经过CNN的feature map和downsampled mask label with size HxWx1。
PROTOTYPE ACTIVATION MODULE
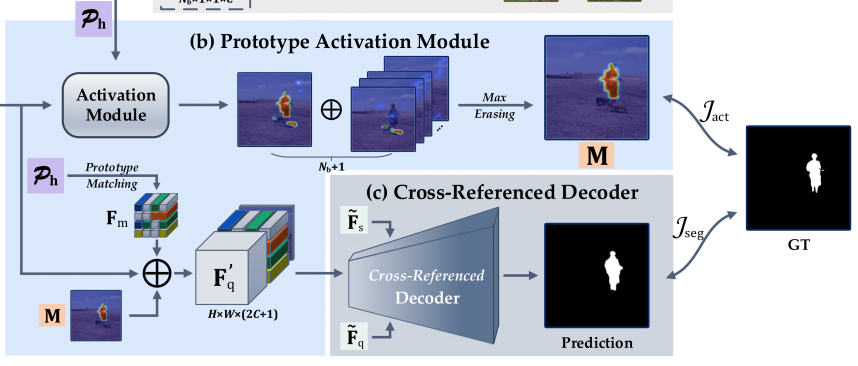
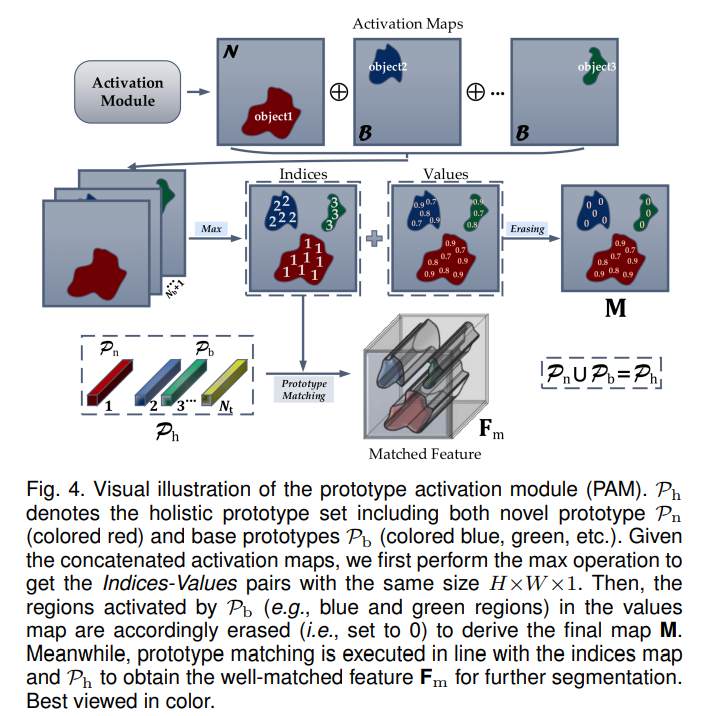
holistic prototype $P_h$是novel class(in meta-test phase, when in meta-train it belong to base category)$P_n$和$P_b$的集合。
对每个class k,计算$F_q$和$P_n^k$的匹配度,其中+代表concatenated,$g_\phi$是11的卷积再加激活函数,这里用的是sigmoid,为了让output在[0,1]这个区间 $$ A_k^{ij}=g_\phi(F_q^{ij}+P^k_h) $$ 然后他先获得一个maximum score,这个怎么得呢?好聪明啊。主要思路就是,如果说这个像素的跟base dataset里面的prototype相似度更高,那我不管这个像素跟query的相似度有多高,直接把这个像素对应的位置置为0。(因为这个像素更有可能属于base dataset中已经学习过的类别) $$ k^ = argmax_k(A_k^{ij}) \ M^{ij}=A_{k^}^{ij} ,\ if \ k^=1 \ otherwise \ 0 $$
下面这一步也很聪明,因为一般做FSS的话,都是有个expand + concat的操作的。然而这里有好多个原型,他就不做全局的expand了,因为前面不是已经做了匹配度计算了么,所以直接在对应位置做expand就好了,具体可见下图
CROSS-REFERENCE DECODER
LOSS
