
This paper is from ICCV 2019. It addressed detection tasks R-CNN based network. However, it simply uses a shared classifier( mlp, I think) and bbox regressor, which is put forward in R-CNN though, to get predictions. Also, it tries a new form loss function out and gets a relatively large promotion.
ABSTRUCT & INTRODUCTION
The model is mainly consist of two modules, i.e.,
- a meta feature learner.
- a light-weight feature reweighting module.
The training process is corresponding to two-phase learning scheme,
- first learn meta features and good reweighting module from base classes.
- fine-tune the detection model to adapt to novel classes.
Though it contains two-phase training, it’s an end-to-end method.
METHOD
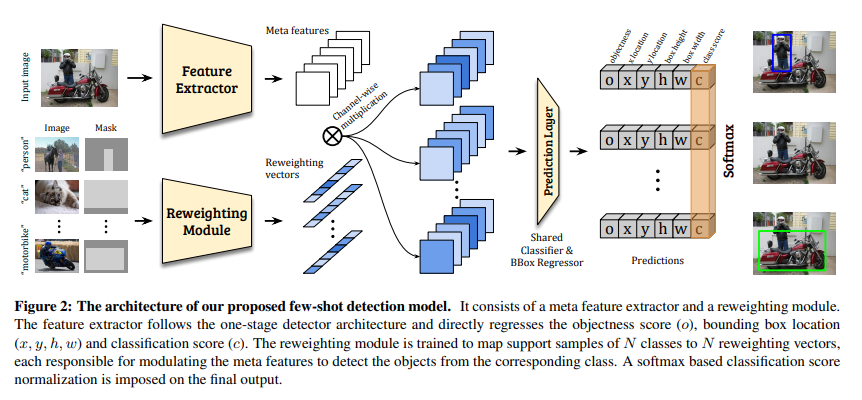
Reweighting Module
This module taking the support examples as input learns to embed support information into reweighting vectors and adjusts the contribution of each meta feature of the query image accordingly for the following detection prediction module. It is like what is used in BAM. However, in BAM it just uses global max pooling ( or global average pooling, whatever), which is not learnable, to get the prototype vectors. This paper uses a learnable layer to get prototype vectors. After that, they apply prototype vectors to obtain the class-specific feature Fi for novel class i by F_i = F \times w_i, where \times means channel-wise multiplication.
Shared Classifier & BBox Regressor
There aren’t any details about Shared Classifier & BBox Regressor module. I simply think this module just being MLP combines BBox Regressor.
Learning Scheme
In the first stage, they just feed the model with abundant base images with annotations. In this way, the model can learn to coordinate the two modules in the desired way.
In the second stage, they fine-tune the model on both base and novel classes. The training procedure is the same as the first phase, except that it takes significantly fewer iterations for the model to converge.
After two training phases, the model can do a test without a novel class as input (it should not be deemed as a novel class, for it has seen the classes in the second stage) and reweighting module, because it remembers the prototype vectors of all class and just do inference in novel images.
LOSS FUNCTION
It is intuitive to use binary cross-entropy as a detection loss function, regressing 1 if the object is the target class and 0 otherwise. However, binary cross-entropy strives to produce balanced positive and negative predictions and could not remove such false predictions. Instead, they adopt a softmax layer to calibrate the classification scores among different classes. It can be denoted as \hat c_i = \frac{e^{c_i}}{\sum_{j=1}^Ne^{c_j}}. Then, the loss function is below: $$ L_c= -\sum_{i=1}^{N}1(·,i)log(\hat c_i) $$
where 1(·, i) is an indicator function for whether the current anchor box really belongs to class i or not. Finally, the overall loss function is $$ L_{det} = L_c + L_bbx + L_{obj} $$