
从TPAMI20那篇过来的,主要想看一下哪里说的middle-level feature
ABSTRACT & INTRODUCTION
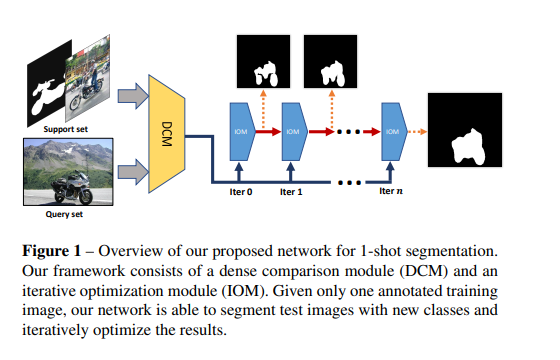
consists of
- a two-branch dense comparison module
- performs multi-level feature comparison between the support image and the query image
- an iterative optimization module
- iteratively refines the predicted results.
有趣的地方
- 先前的工作,从1-shot拓展到k-shot时,都是用non-learnable fusion,这篇文章中用的是attention mechanism。
- 做test的时候,不再输入support image mask了,而是输入support image bounding box.
METHOD
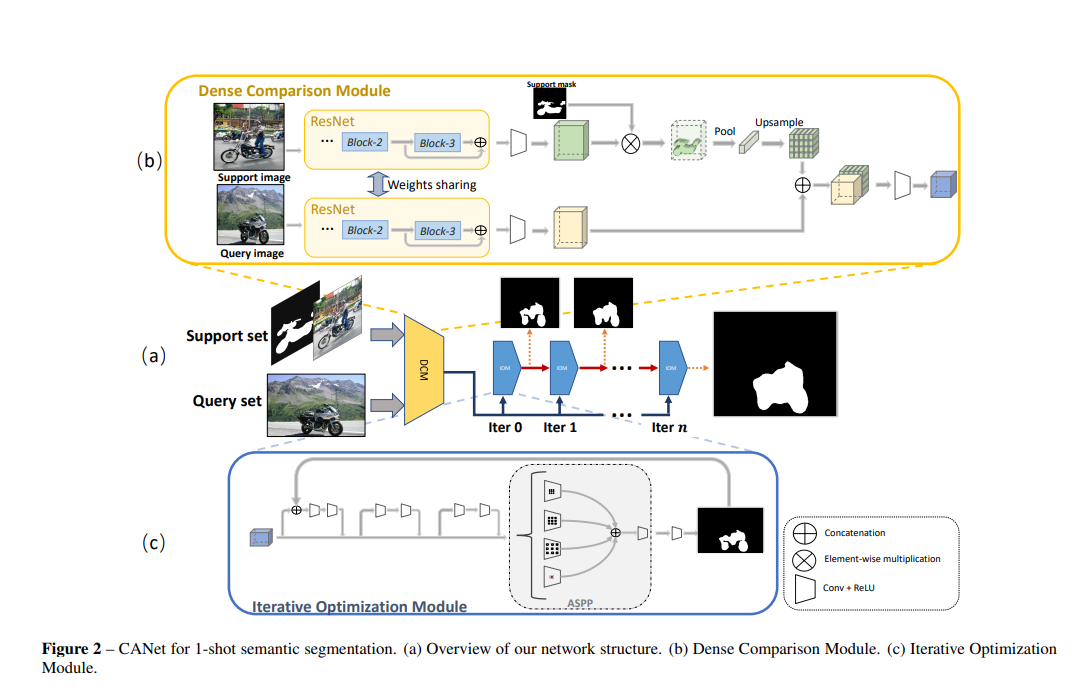
DENSE COMPARISON MODULE
在CNN中
- feature in low layers often relate to low-level cues 比如颜色,边缘。个人感觉是因为感受野不够大
- feature in higher layers relate to object-level concepts 比如物品种类
因为他们要求模型训练完之后具备一定的generalization,而middle-level fature有可能会包含来自没见过的物体的part。比如说训练的时候见过小轿车,那么在测试中,我就比较容易根据middle-level中的轮胎来segment公交车。(make sense)
dialated convolution空洞卷积
以下来自知乎
7 x 7 的卷积层的正则等效于 3 个 3 x 3 的卷积层的叠加。而这样的设计不仅可以大幅度的减少参数,其本身带有正则性质的 convolution map 能够更容易学一个 generlisable, expressive feature space。这也是现在绝大部分基于卷积的深层网络都在用小卷积核的原因。
传统卷积核的本质问题:pool减小图片尺寸,upsampling增大图片尺寸,在这个过程中肯定有信息丢失掉了。因此空洞卷积就是不通过pooling也能获得较大感受野的方法
dialated convolution的优点:内部数据结构的保留和避免使用 down-sampling 。
具体的,他们把Resnet分成4个block,只用block2和block3的输出,将其concat到一起。后面就是support feature与support feaure相乘来把背景像素清0,avg pool之后repeat到之前的维度和query feature concat到一起,比较常规。
INERATIVE OPTIMIZATION MODULE
每一次迭代中,首先进行如下运算。其中$M$是output of the residual blocks,$x$是DCM模块的输出,$y_{t-1}$是上一个迭代块的输出,$F$是concat之后再经过两层卷积层。 $$ M_t = x + F(x,y_{t-1}) $$ 对$M_t$,再经过两层vanilla residual blocks。然后再经过ASSP模块输出。
就差不多这么迭代n次
ATTENTION MECHANISM FOR K-SHOT SEGMENTATION
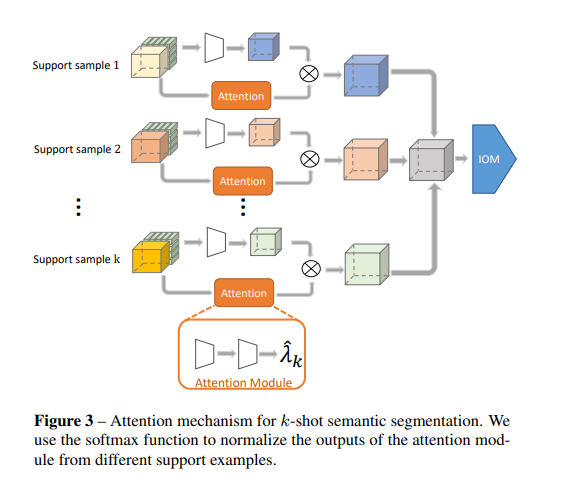
这也算attention嘛? query, key, value分别是什么?
在attention模块中,经过两层卷积再softmax得到$\hat\lambda_k$,然后把$\hat\lambda_k$和经过卷积的support sample n相乘。
ABLATION STUDY
Feature for Comparison
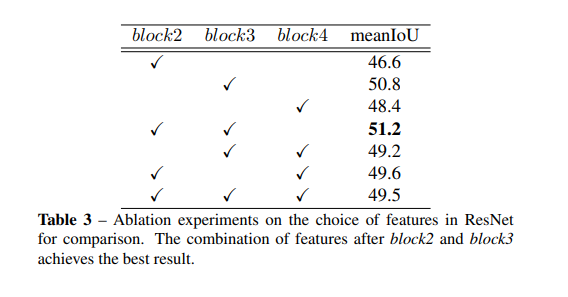
这里说单个的话block2效果是最好的,整体上block2+block3的效果最好。嗯,比较可信。
其中提了一嘴While block4 corresponds to high-level features, e.g., categories, and incorporates a great number of parameters (2048 channels), which makes it hard to optimize under the fewshot setting.
深有同感!
Attention vs. Feature Fusion vs. Mask Fusion
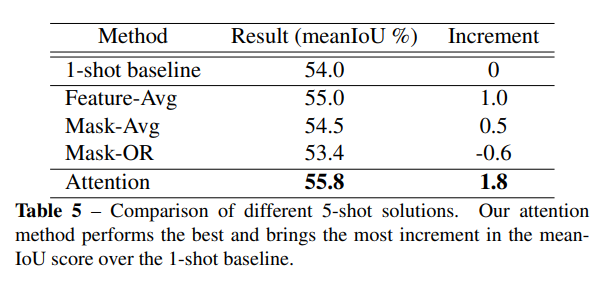
从这里可以看出Attention效果是最好的。但是相比来说的话还是多了两层卷积,增加了参数。Feature-Avg表现不错,感觉跟attention也差不多了(主要是没有另外加参数)。Mask-Avg这么奇怪的想法竟然也有效,能+0.5。还有Mask-OR你要笑死我嘛,怎么还没1-shot高啊,怎么回事啊小老弟,纯纯的帮倒忙。